what is the quotient in simplest form? Stay any restrictions on the very well. Leave in factored form. Plus show work

Answers
The quotient is \(\frac{(z-2)(z+4)}{(z+2)}\) and the restriction on the variable is z≠-2.
Describe fraction?A fraction is a number that represents a part of a whole. It is represented by two numbers, one above the other, separated by a horizontal or slanted line. The number above the line is called the numerator, and the number below the line is called the denominator. The denominator represents the total number of equal parts into which the whole is divided, while the numerator represents the number of those parts that are being considered.
For example, the fraction 3/4 represents three parts out of a total of four equal parts, or three-quarters of the whole. Fractions can be used to represent numbers that are not whole numbers, such as 1/2, 2/3, 5/8, and so on. They can also be used to compare quantities, add and subtract values, and perform other mathematical operations.
First, factor the given expressions:
(z²-4) = (z-2)(z+2)
(z²+z-12) = (z+4)(z-3)
Substitute these expressions in the given expression:
\(\frac{(z-2)(z+2)}{(z-3)} / \frac{(z+2)}{(z+4)(z-3)}\)
Change the division sign to multiplication by flipping the second fraction:
\(\frac{(z-2)(z+2)}{(z-3)} * \frac{(z+4)(z-3)}{(z+2)}\)
Cancel out common factors in the numerator and denominator:
\(\frac{(z-2)(z+4)}{(z+2)}\)
Therefore, the quotient is \(\frac{(z-2)(z+4)}{(z+2)}\) and the restriction on the variable is z≠-2.
To know more about quotient visit:
https://brainly.com/question/12938473
#SPJ1
Related Questions
Change.83 to a fraction.
83
[?]
it’s for acellus and it’s not 100 apparently please help as soon as you can
Answers
Answer:
83/100
Step-by-step explanation:
Decimals to fractions
N over three point N over four
Write without exponents.י
Answers
Answer:
N
---
3.N
--------
4
Step-by-step explanation:
PLEASE I NEED HELP
What is the slope-intercept form of the linear equation 2x + 3y = 6?
Answers
Answer:
y= 2/3x + 2
Step-by-step explanation:
find the solution of pair of equation y=0 and y= -6
Answers
Answer:
Step-by-step explanation:
there is no soltion because it is not intersects
Answer:
No solution as it will not intersect.
a circle is inscribed in a unit square. a smaller square is then inscribed within the circle. what is the side length of the smaller square?
Answers
To solve this problem, we need to use some basic geometry concepts. First, we know that the diagonal of a unit square is the square root of 2, since the sides are of length 1. The side length of the smaller square inscribed within a circle inscribed in a unit square is 1.
Next, we know that the circle inscribed in the square will have a diameter equal to the diagonal of the square, which is the square root of 2. The radius of the circle will therefore be half of the diameter, which is sqrt(2)/2.
Now we can use the radius of the circle to find the side length of the smaller square inscribed within it. If we draw the diagonal of the smaller square, it will be twice the radius of the circle, or sqrt(2). This is because the diagonal of the square passes through the center of the circle and therefore has a length equal to twice the radius.
We can then use the Pythagorean theorem to find the length of each side of the smaller square. If we let x be the side length of the smaller square, then we have:
x^2 + x^2 = 2
2x^2 = 2
x^2 = 1
x = 1
Therefore, the side length of the smaller square is 1, which makes sense since it is inscribed within a unit square.
For more questions on geometry
https://brainly.com/question/24375372
#SPJ11
michael is running for president. the proportion of voters who favor michael is 0.8. a simple random sample of 100 voters is taken. (a) what is the expected value of the sampling distribution of p?
Answers
The expected value of the sampling distribution of p is 0.8.
A statistic's probability distribution is called a sampling distribution when it is calculated from a larger number of samples taken from a particular population. The distribution of frequencies for a variety of outcomes that could possibly occur for a statistic of a population is known as the sampling distribution of that population.
The normal distribution, which is also known as the Gaussian distribution, is symmetric about the mean. It demonstrates that data close to the mean occur more frequently than data far from the mean. The normal distribution is depicted graphically as a "bell curve."
the sampling distribution of sample proportion will be a normal distribution with mean
\(\mu_{p}\) = p = 0.8
know more about mean here: https://brainly.com/question/17002881
#SPJ4
Jennifer works at the local hamburger stand one of her duties is to refill cat soups bottles a bottle contained 2 oz of ketchup is placed on the counter Jennifer pours more ketchup and a rate of 1/2 oz per second which equation best represents y the ounces of ketchup in the bottle after x seconds
Answers
Jill wants to have ride at least 144 miles on her bike. Her riding speed is 9 miles per hour. Which inequality(s) represents how many h hours she needs to ride?
Answers
Hey there!
Let's make an equation
=> 9h = 144
{ Make h the subject of formula}
=> 9h = 144
=> 9h/9 = 144/9
=> h = 144/9
=> h = 16
The angle of elevation at the top of a tower from a point on the ground which is 30m away from the foot of the tower is 30degrees. Find the height of the tower
Answers
The height of the tower is approximately 15.59 meters.
Let the height of the tower be h meters. Then, from the given information, we can draw a right-angled triangle with the base as 30m, the height as h meters, and the angle of elevation as 30 degrees. We can use the tangent ratio to find the height of the tower:
tan 30° = h / 30
Simplifying the above equation, we get:
h = 30 x tan 30°
Using the trigonometric table, we can find that the value of tangent 30 degrees is 1/√3. So,
h = 30 x 1/√3
h = 30/√3 x √3/√3
h = 30√3/3
h = 10√3 ≈ 15.59 m
Therefore, the height of the tower is approximately 15.59 meters.
For more questions like Height visit the link below:
https://brainly.com/question/30831218
#SPJ11
1) 7 is 15 % of what number ?
2) 25 is what percent of 60%
3) what is 0.15% of 250?
4) 300 is 250% of what Number
Please show work

Answers
Answer:
\( \boxed{ \sf{1. \: \: \: \: 46.67}}\)
\( \boxed{ \sf{2. \: \: \: \: 41.67\%}}\)
\( \boxed{ \sf{3. \: \: \: \: 0.375}}\)
\( \boxed{ \sf{4. \: \: \: \: 120}}\)
Step-by-step explanation:
1. Let the number be x
\( \sf{15\% \: of \: x = 7}\)
\( \dashrightarrow{ \sf{ \frac{15}{100}x = 7}} \)
\( \dashrightarrow{ \sf{0.15x = 7}}\)
\( \dashrightarrow{ \sf{x = \frac{7}{0.15}}}\)
\( \dashrightarrow{ \sf{46.67}}\)
-------------------------------------------------------------
2. Let the percent be x %
\( \sf{x\% \: of \: 60 = 25}\)
\( \dashrightarrow{ \sf{ \frac{x}{100} \times 60 = 25}}\)
\( \dashrightarrow{ \sf{ \frac{60}{100}x = 25}} \)
\( \dashrightarrow{ \sf{0.6x = 25}}\)
\( \dashrightarrow{ \sf{x = \frac{25}{0.6} }}\)
\( \dashrightarrow{ \sf{41.67\%}}\)
-----------------------------------------------------------
3. \( \sf{0.15\% \: of \: 250}\)
\( \dashrightarrow{ \sf{ \frac{0.15}{100} \times 250}}\)
\( \dashrightarrow{ \sf{0.375}}\)
----------------------------------------------------------
4. Let the number be x
\( \sf{250\% \: of \: x = 300}\)
\( \dashrightarrow{ \sf{ \frac{250}{100} \times x = 300}}\)
\( \dashrightarrow{ \sf{2.5x = 300}}\)
\( \dashrightarrow{ \sf{x = \frac{300}{2.5} }}\)
\( \dashrightarrow{ \sf{x = 120}}\)
Hope I helped!
Best regards! :D
Trina must spend at least 45 minutes, m, studying for her test
Answers
The inequality that describes that Trina must spend at least 45 minutes studying for her test at x ≥ 45 min.
How to write the inequality ?In mathematics, "inequality" refers to a relationship between two expressions or values that is not equal to each other. Therefore, inequality emerges from a lack of balance. In Algebra, an inequality is a mathematical statement that uses the inequality symbol to illustrate the relationship between two expressions.
Trina is to spend at least 45 minutes studying for her test which means that she can either spend 45 minutes studying, or more than 45 minutes.
The inequality for this is therefore:
x ≥ 45
Assuming that the minutes she spends studying is x.
Find out more on inequalities at https://brainly.com/question/25275758
#SPJ1
Full question is:
Trina must spend at least 45 minutes studying for her math test. (find the inequality)
someone help me please with this algebra problem
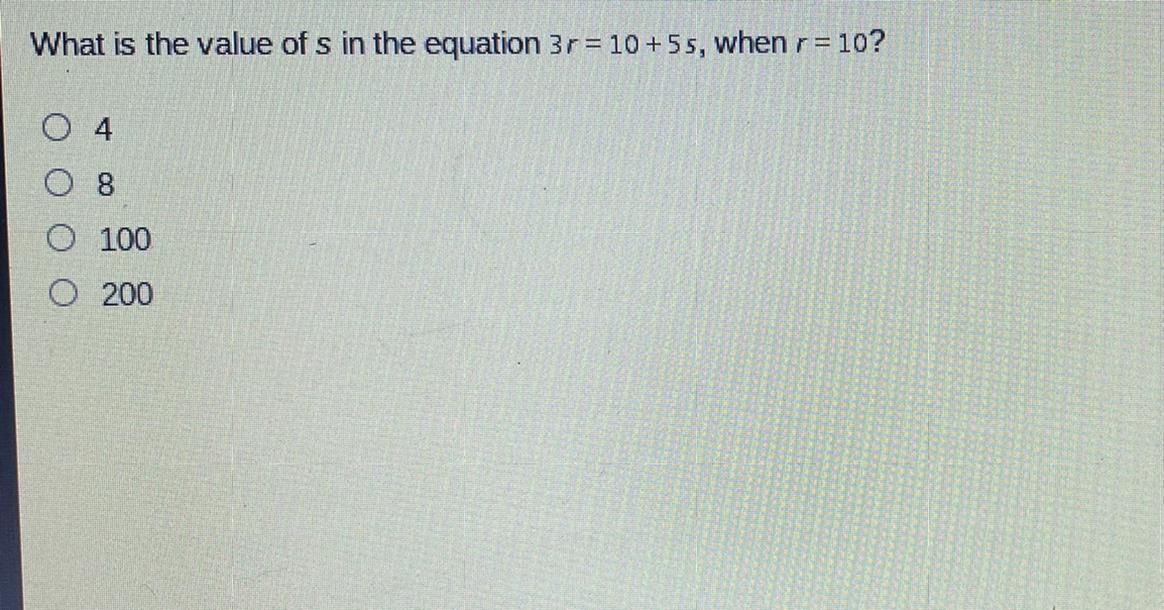
Answers
Answer:
4
Step-by-step explanation:
3r = 10 + 5s
r = 10
3(10) = 10 + 5s
30 = 10 + 5r
20 = 5r
r = 4
To solve the equation shown, Darren thinks you should subtract 2.5 from ach side while Eddie thinks you should divide both sides by 2.5. Who do you gree with, and what value of n makes the equation true?
//WILL GIVE THE BRAINIEST//
Answers
Answer:
n = 5
Step-by-step explanation:
hope this helped!
mark me brainliest :D
Where does today come before yesterday? You guy can do this! :)
Answers
Answer:
in the dictionary.
Step-by-step explanation:
Answer:
Well the rationale utilized to unravel this enigma is that within the word reference words or letters are sorted out In order and subsequently Nowadays comes before Recently since within the letter set arrange or in order the Letter T comes some time recently the Letter Y.
Step-by-step explanation:
An independent set in a graph is a set of vertices S⊆V that contains no edge (so no pair of neighboring vertices is included). The max independent set problem is to find an independent set of maximum size in a graph G. (a) Write the max independent set problem as an integer linear program. (b) Write an LP relaxation for the max independent set problem. (c) Construct an example (a family of graphs) to show that the ratio LP-OPT / OPT can be at least cn where c>0 is some absolute constant and n is the number of vertices of the graph. (d) What is the (exact) relation between the size of a max independent set and the size of min vertex cover of a graph? (e) Using this relation, what does the 2-approximation algorithm for vertex cover imply for an approximation algorithm for max independent set?
Answers
The independent set in a graph is a set of vertices that contain no edges. So, no neighboring vertices are included. The max independent set problem is to get an independent set of maximum size in graph G.
The solution for this question is discussed below:
a) The integer linear program for the max independent set problem is as follows:
maximize ∑x_i Subject to: x_i+x_j ≤ 1 {i,j} ∈ E;x_i ∈ {0, 1} ∀i. The variable x_i can represent whether the ith vertex is in the independent set. It can take on two values, either 0 or 1.
b) The LP relaxation for the max independent set problem is as follows:
Maximize ∑x_iSubject to:
xi+xj ≤ 1 ∀ {i, j} ∈ E;xi ≥ 0 ∀i. The variable xi can take on fractional values in the LP relaxation.
c) The family of graphs is as follows:
Consider a family of graphs G = (V, E) defined as follows. The vertex set V has n = 2^k vertices, where k is a positive integer. The set of edges E is defined as {uv:u, v ∈ {0, 1}^k and u≠v and u, v differ in precisely one coordinate}. It can be shown that the size of the max independent set is n/2. Using LP, the value can be determined. LP provides a value of approximately n/4. Therefore, the ratio LP-OPT/OPT is at least c/4. Therefore, the ratio is in for a constant c>0.
d) The size of a max-independent set is equivalent to the number of vertices minus the minimum vertex cover size.
e) The 2-approximation algorithm for vertex cover implies a 2-approximation algorithm for the max independent set.
To know more about the independent set, visit:
brainly.com/question/31418821
#SPJ11
Solve:
-11 - 79 +5g = 3
Answers
Answer:
g=18.6
Step-by-step explanation:
-11-79+5g=3
-90+5g=3
5g=3+90
5g=93
g=93/5=18.6
g=18.6
what is the answer for , 5ײ + 1 + × + 3ײ
Answers
Explanation:
-collect like terms. We have 5x^2 and 3x^2. Add those two and then rewrite the equation in quadratic form. So the answer is 8x^2+x+1
Counting jails and prisons, approximately how many citizens are incarcerated? a. 1 million b. 2.3 million c. 3 million d. 4.3 million.
Answers
In September 2021, the approximate number of citizens incarcerated in jails and prisons is around 2.3 million.
It is important to note that this figure can vary over time due to changes in policies, criminal justice reforms, and other factors. The incarcerated population includes individuals who have been convicted of crimes and are serving their sentences, as well as those who are awaiting trial or have been sentenced but not yet transferred to a correctional facility.
These numbers can vary between different countries and jurisdictions. To obtain the most accurate and up-to-date information on current incarceration rates, it is advisable to refer to official sources such as the U.S. Bureau of Justice Statistics or relevant governmental organizations in your country.
Learn more about number here:
https://brainly.com/question/3589540
#SPJ11
If it has been determined that the probability of an earthquake occurring on a certain day in a certain area is 0.02, what are the odds of an earthquake occurring?
a) 49 to1
b) 1 to 50
c) 1 to 48
d) 1 to 49
Answers
The odds of an earthquake is 1 to 50
How the odds of an earthquake is 1 to 50?We need to calculate the odds of an earthquake occurring. Odds are calculated as the ratio of the probability of the event happening to the probability of the event not happening.
The probability of an earthquake occurring is 0.02, so the probability of an earthquake not occurring is 1 - 0.02 = 0.98.
The odds of an earthquake occurring are therefore 0.02 / 0.98 = 0.0204.
To express the odds in the form of a ratio, we can write 0.0204 as a fraction and simplify it.
0.0204 = 204/10000 = 51/2500
The simplified ratio is 51 to 2500.
To convert the ratio to the requested format, we need to subtract 1 from each part of the ratio and express it as a whole number ratio.
51/2500 - 1 = 50/2500 = 1/50
So, the odds of an earthquake occurring are 1 to 50.
Therefore, the answer is (b) 1 to 50.
Learn more about Earthquake
brainly.com/question/29500066
#SPJ11
Consider this research hypothesis: If skin cancer is related to UV light, then people with a high exposure to UV light will have a higher frequency of skin cancer. Which portion of this hypothesis contains the testable proposed relationship between the variables? a All of the choices are correct b None of the choices are correct c If skin cancer is related to UV light
d Then people with a high exposure to UV light will have a higher frequency of skin cancer
Answers
Answer is d. The testable proposed relationship between the variables in the research hypothesis is: "Then people with a high exposure to UV light will have a higher frequency of skin cancer." This portion of the hypothesis specifically establishes the expected connection between UV light exposure and the occurrence of skin cancer, allowing for investigation and data collection to either support or refute the hypothesis.
A hypothesis is a tentative explanation for a phenomenon that is based on prior knowledge and observations. It is essential to have a testable hypothesis to ensure that the research study can be conducted in a rigorous and systematic manner. A testable hypothesis allows researchers to design experiments that can collect data to support or refute the hypothesis. Without a testable hypothesis, researchers may not be able to generate meaningful results that contribute to scientific knowledge.
A critical aspect of hypothesis testing is making clear and specific predictions about the relationship between the variables. In this case, the researchers are predicting that people with a high exposure to UV light will have a higher frequency of skin cancer. This prediction is specific because it defines the level of UV light exposure that is expected to lead to a higher frequency of skin cancer. It is also measurable because the frequency of skin cancer can be quantified through data collection. By making this clear and specific prediction, the researchers can test their hypothesis and determine whether the data support or refute their hypothesis.
To know more about hypothesis visit:-
https://brainly.com/question/1866915
#SPJ11
PLS HELP IM STUCK PLS

Answers
Step-by-step explanation:
y= x/5 -10
inverse meaning x= y/5 -10
you solve and simplify to get
y= 5x+50
so ans is 50
Brainliest?
Question 5 16 pts 5 1 Details Consider the vector field F = (xy*, x*y) Is this vector field Conservative? Select an answer If so: Find a function f so that F = vf f(x,y) + K Se f. dr along the curve C
Answers
The line integral ∫C F · dr, where dr is the differential of the position vector along the curve C, can be evaluated as ∫C ∇f · dr = f(Q) - f(P), where Q and P represent the endpoints of the curve C.
The vector field F = (xy, x*y) can be determined if it is conservative by checking if its components satisfy the condition of being partial derivatives of the same function. If F is conservative, we can find a potential function f(x, y) such that F = ∇f, and use it to evaluate the line integral of F along a curve C.
To determine if the vector field F = (xy, x*y) is conservative, we need to check if its components satisfy the condition of being partial derivatives of the same function. Taking the partial derivative of the first component with respect to y yields ∂(xy)/∂y = x, while the partial derivative of the second component with respect to x gives ∂(x*y)/∂x = y. Since these partial derivatives are equal, we can conclude that F is a conservative vector field.
If F is conservative, there exists a potential function f(x, y) such that F = ∇f, where ∇ represents the gradient operator. To find f, we can integrate the first component of F with respect to x and the second component with respect to y. Integrating the first component, we get ∫xy dx = \(x^2y/2\) + K1(y), where K1(y) is a constant of integration depending on y. Integrating the second component, we have ∫x*y dy = \(xy^2/2\) + K2(x), where K2(x) is a constant of integration depending on x. Therefore, the potential function f(x, y) is given by f(x, y) = \(x^2y/2 + xy^2/2\) + C, where C is the constant of integration.
To evaluate the line integral of F along a curve C, we can use the potential function f(x, y) to simplify the calculation.
To learn more about line integral, refer:-
https://brainly.com/question/29850528
#SPJ11
90% of the stores at a shopping mall sell clothing. If 63 of the stores sell clothing, how many total stores are at the mall?
Answers
70 x .90 (or 90%)= 63 stores that sell clothing.
Numbers that describe diversity in a distribution are referred to as measures of 1) variability. 2) central tendency. 3) standard deviation. 4) association.
Answers
Measures of variability describe diversity in a distribution.
Measures of variability describe the spread or dispersion of values in a distribution. They provide information about how spread out or clustered the data points are. Common measures of variability include the range, variance, and standard deviation.
Measures of central tendency, on the other hand, describe the center or average of a distribution. They provide information about the typical or central value around which the data points are located. Common measures of central tendency include the mean, median, and mode.
Standard deviation is a specific measure of variability that quantifies the average amount by which data points in a distribution deviate from the mean. Association refers to the relationship or connection between two or more variables in a dataset, often analyzed using correlation or regression analysis. It is not a measure of diversity in a distribution.
To know more about variability,
https://brainly.com/question/29355567
#SPJ11
The temperature dropped 12°F one hour ago. If the current temperature is 50°F, to find the temperature an hour ago, what operation would you do?
Group of answer choices
Divide
Subtract
Add
Mutiply
Answers
What are the three types of horizontal asymptotes?
Answers
There are 3 cases to consider when determining horizontal asymptotes:
1) Case 1: if: degree of numerator < degree of denominator. then: horizontal asymptote: y = 0 (x-axis)
2) Case 2: if: degree of numerator = degree of denominator.
3) Case 3: if: degree of numerator > degree of denominator.
5x-2y=11 and 3x+4y=4
Find the value of x and y in equation.
Answers
(1)×3 and (2)×5
15x-9y=33-(3)15x+20y=20-(4)Subtract both
\(\\ \sf\longmapsto -29y=13\)
\(\\ \sf\longmapsto y=\dfrac{-13}{29}\)
Put in eq(1)\(\\ \sf\longmapsto 5x+\dfrac{-117}{29}=11\)
\(\\ \sf\longmapsto 5x=11+\dfrac{117}{29}=\dfrac{261+117}{29}=\dfrac{278}{29}\)
\(\\ \sf\longmapsto x=\dfrac{278}{145}\)
For the polynomial function: \[ f(x)=x^{3}+3 x^{2}-2 x+1 \] is 1 the upper bound, yes or no. Explain your answer using Synthetic Division and the coefficients of the last line.
Answers
No, 1 is not an upper bound for the polynomial function \(\( f(x) = x^3 + 3x^2 - 2x + 1 \)\). This is determined by performing synthetic division with 1 as the test value and observing that all the coefficients in the bottom row are positive.
To determine if 1 is an upper bound for the polynomial function\(\( f(x) = x^3 + 3x^2 - 2x + 1 \)\), we can use synthetic division.
Performing synthetic division with 1 as the test value, we set up the synthetic division as follows:
1 | 1 3 -2 1
|_______
1 4 2 3
The numbers in the bottom row, 1, 4, 2, 3, represent the coefficients of the quotient polynomial.
To determine if 1 is an upper bound, we look at the signs of the coefficients. In this case, all the coefficients in the bottom row are positive.
Since all the coefficients are positive, we can conclude that 1 is not an upper bound for the polynomial function.
To know more about polynomial function refer here:
https://brainly.com/question/29054660#
#SPJ11
Help plz
What different and similar between Rectangle and square
Answers
Definition of Square and Rectangle
Square: A square is a closed two-dimensional plane figure with four sides. All the four sides of the square are of equal measure. Also, the four interior angles of a quadrilateral are of 9o degrees. In other words, a square is considered as a quadrilateral or a 4-sided polygon. Since all the angles are of equal measure, it is considered as an equiangular quadrilateral.
Rectangle: A rectangle is a quadrilateral with four sides. The opposite side of a rectangle is parallel to each other. It means that the opposite faces of the rectangle are of equal measure. A rectangle has four angles, each measuring about 90 degrees. As like square, a rectangle is also called an equiangular quadrilateral.
Find the approximate height of the cylinder. Use 3.14 for π.
Volume = 146.952 cm3 A cylinder is shown. The diameter is labeled six centimeters.
Answers
Answer: The height is 5.2 cm.
Step-by-step explanation:
146.952 = n r^2 h
146.952= 3.14 * 9 *h
146.952= 28.26 h divide both sides by 28.26
h = 5.2